
The Cisco Live Network Operations Center (NOC) deployed Cisco Umbrella for Domain Name Service (DNS) queries and security. The Security Operations Center (SOC) team integrated the DNS logs into Splunk Enterprise Security and Cisco XDR.
To protect the Cisco Live attendees on the network, the default Security profile was enabled, to block queries to known malware, command and control, phishing, DNS tunneling and cryptomining domains. There are occasions when a person needs to go to a blocked domain, such a live demonstration or training session.

During the Cisco Live San Diego 2025 conference, and other conferences we have worked in the past, we have saw domain names that are two to three words in a random order like “alphabladeconnect[.]com” as an example. These domains are linked to a phishing campaign and are sometimes not yet identified as malicious.
Ivan Berlinson, our lead integration engineer, created XDR automation workflows with Splunk to identify Top Domains seen in the last six and 24 hours from the Umbrella DNS logs, as this can be used to alert to an infection or campaign. We noticed that domains that followed the three random names pattern started to showing up, like 23 queries to shotgunchancecruel[.]com in 24 hours.
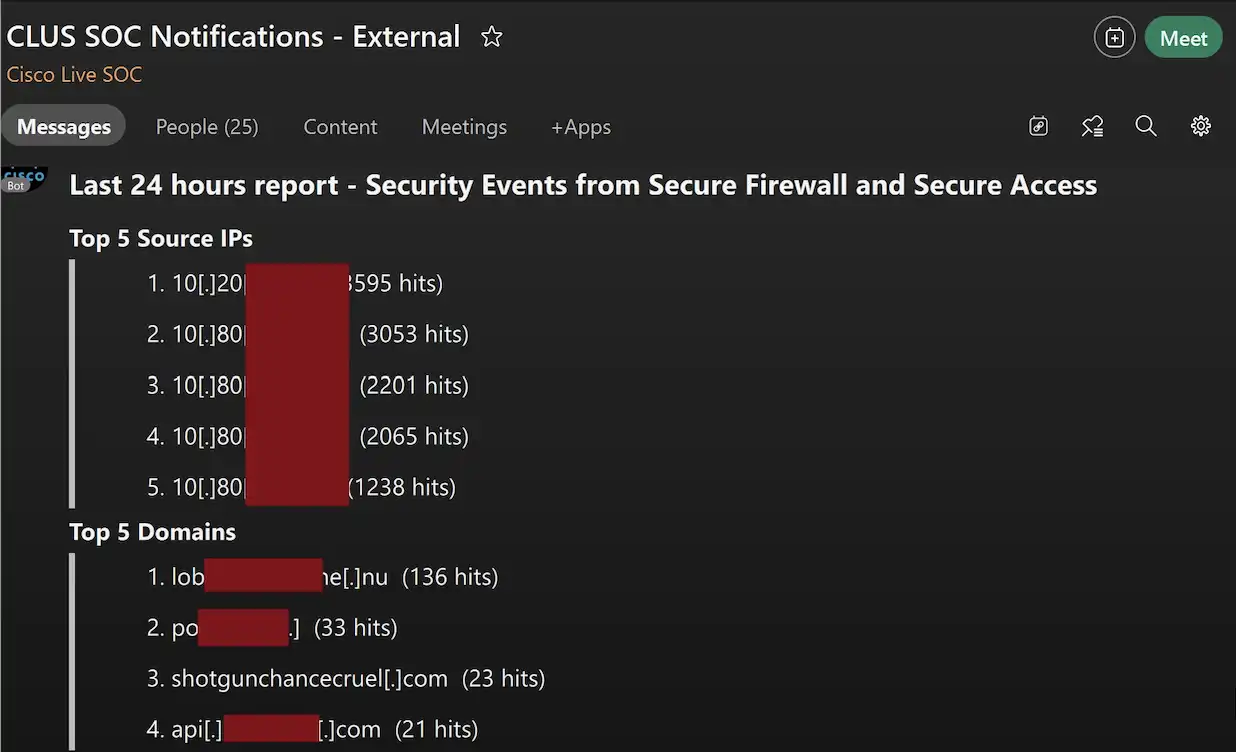
This got me thinking, “Could we catch these domains using code and with our push to use AI, could we leverage AI to find them for us?”
The answer is, “Yes”, but with caveats and some tuning. To make this possible, I first needed to figure out the categories of data I wanted. Before the domains get marked as malicious, they are usually categorized as shopping, advertisements, commerce, or uncategorized.
I started off running a small LLM on my Mac and chatting with it to determine if the functionality I want is there. I told it the requirements of needing to be two-three random words, and to tell me if it thinks it is a phishing domain. I gave it a few domains that we already knew were malicious, and it was able to tell that they were phishing according to my criteria. That was all I needed to start coding.
I made a script to pull down the allowed domains from Umbrella, create a de-duped set of the domains and then send it to the LLM to process them with an initial prompt being what I told it earlier. This did not work out too well for me, since it was a smaller model. I overwhelmed it with the amount of data and quickly broke it. It started returning answers that did not make sense and different languages.
I quickly changed the behavior of how I sent the domains over. I started off sending domains in chunks of 10 at a time, then got up to 50 at a time since that seemed to be the max before I thought it would become unreliable in its behavior.
During this process I noticed variations in its responses to the data. This is because I was giving it the initial prompt I created every time I sent a new chunk of domains, and it would interpret that prompt differently each time. This led me to modify the model’s modelfile. This file is used as the root of how the model will behave. It can be modified to change how a model will respond, analyze data, and be built. I started modifying this file from being a general purpose, helpful assistant, to being a SOC assistant, with attention to detail and responding only in JSON.
This was great, because now it was consistently responding to how I wanted it to, but there were many false positives. I was getting about a 15–20% false positive (FP) rate. This was not acceptable to me, as I like to have high fidelity alerts and less research when an alert comes in.
Here is an example of the FP rate for 50 at this point and it was oftentimes much higher:
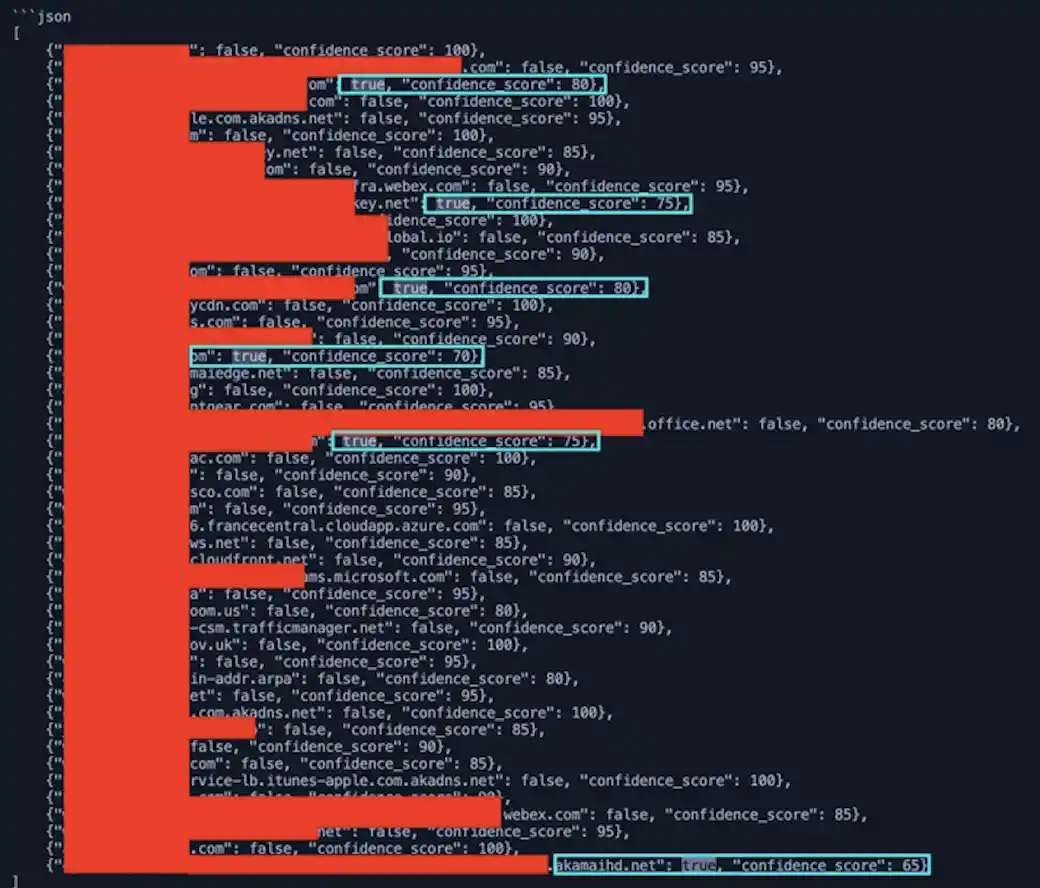
I started tuning the modelfile to tell the model to give me a confidence score as well. Now I was able to see how confident it was in its determination. I was getting a ton of 100% on domains for AWS, CDNs, and the like. Tuning the modelfile should fix that though. I updated the modelfile to be more specific in its analysis. I added that there should not be any delimiters, like a dot or dash between the words. And I gave it negative and positive samples it could use as examples when analyzing the domains fed to it.
This worked wonders. We went from a 15–20% FP rate to about 10%. 10% is much better than before, but that’s still 100 domains out of 1000 that might need to check. I tried modifying the modelfile more to see if I could get the FP rate down, but with no success. I swapped to a newer model and was able to drop the FP rate to 7%. This shows that the model you start with will not always be the model you end up with or will suit your needs the most.
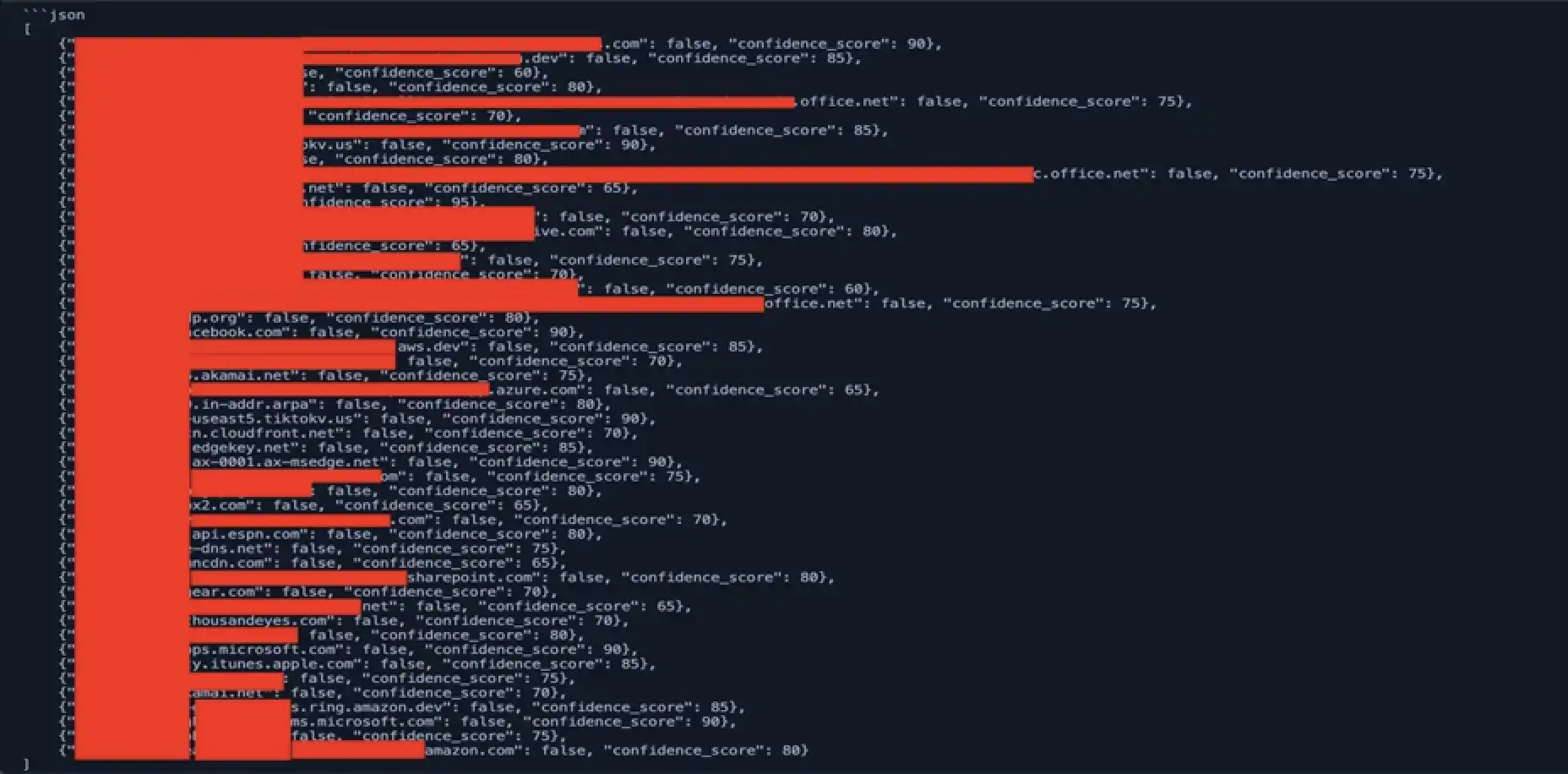
At this point, I was fairly happy with it but ideally would like to get the FP rate down even further. But with the model’s current capabilities, it was able to successfully identify phishing domains that were not marked as malicious, and we added them to our block list. Later, they were updated in Umbrella to be malicious.
This was a great feat for me, but I needed to go further. I worked with Christian Clasen, our resident Umbrella/Secure Access expert and was able to get a slew of domains associated with the phishing campaign and I curated a training set to fine tune a model.
This task proved to be more challenging than I thought, and I was not able to fine tune a model before the event ended. But that research is still ongoing in preparation for Black Hat USA 2025.
We’d love to hear what you think! Ask a question and stay connected with Cisco Security on social media.
Cisco Security Social Media
LinkedIn
Facebook
Instagram
X
Share: